 Image credit: Google
Image credit: Google
The Problem Statement
This project is aimed at identifying hateful content from social media memes. In general, hateful memes have a more convoluted hidden meaning, woven deep into our social prejudices. Seemingly insignificant differences can completely change how people interpret them. Due to the subtle nature of these memes, people belonging to different classes, societies and gender interpret them differently. All these qualities make the task of detection of hateful memes a lot more challenging and all the more necessary to ensure a safe and wholesome social media experience. In this project, we look into the challenges we face with brute force finetuning for this task and why training with semi-supervised modifications is a necessity.
The Model:
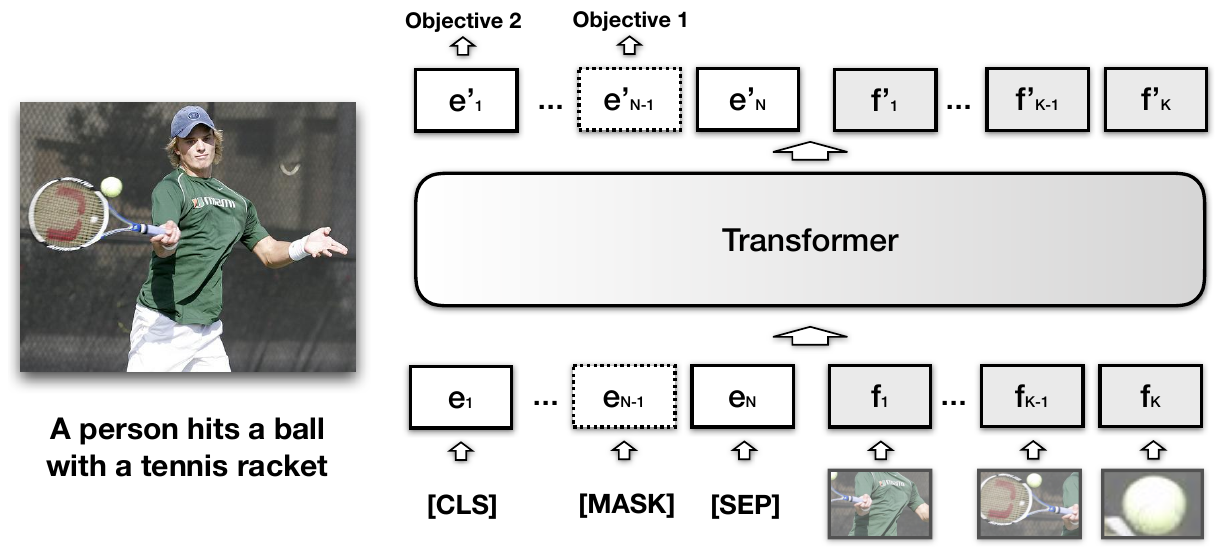
The model we use for experiments is Visual-BERT, which is a transformer encoder based multimodal deep learning model, developed by UCLA-NLP. The model architecture is similar to BERT. The difference is that we also input meme-image embeddings(obtained from bounding boxes predicted by a Mask-RCNN model) concatenated to BERT’s WordPiece embeddings for the meme text. This ensures efficient text-to-image and image-to-text attention that ensures that we can model the subtle interdependencies at play when dealing with multiple modalities.
Finetuning strategies:
-
Community Tags:
We perform image grounding in a self-supervised manner by extracting target community information from the meme image. We collect a Community-dataset comprising of images related to the top-10 targeted communities identified in the Hateful Memes dataset using browser automation. We develop a CNN classifier, which we call the CommNet, and train it on this dataset. After training, we generate the community tag output from CommNet for the entire Hateful Memes dataset.
Output labels with the prediction probability of less than a threshold are discarded. And for the rest, an additional line with information regarding the community information is added to the input meme text. This modified input is provided to the Visual-BERT model during training and inference. This helps the model get details regarding community information contained in the meme, and thus better differentiate between memes with similar text in different contexts.
-
Negative Supervision:
One noticeable feature of the Hatememe dataset was that multiple memes were based upon the same template images. In these cases, if there is a minimal lexical difference in the meme text, the Visual-BERT output [CLS] embeddings are similar, thus resulting in similar prediction probabilities.
Negative supervision aims at learning to differentiate between similar-looking samples. First, we run the Visual-BERT model on each sample in the train split of the Hatememe dataset and store the CLS embeddings for hate and not hate samples separately. For storing, we use Facebook’s fast indexing-based storage FAISS. Then, we iterate on all samples in the training dataset and extract the samples having the opposite training label but the largest cosine similarity of their CLS embeddings. During training, we include an additional negative sampling loss, that is a scaled cosine similarity between the embeddings of the similar sample pair. This ensures that, as training progresses, similar samples having different labels have more distant output embeddings.
-
Monte Carlo Dropout: During inference, we keep random dropout and take the final predicted probability as the mean of the Gaussian distribution generated using the predicted probabilities over 100 runs. Using MC-dropout ensures better-calibrated output probabilities, i.e. generated probabilities reflect the true model confidence in the predicted class.
Debjoy Saha
B.Tech Student
B.tech stduent interested in Multimodal Machine Learning and Speech, Language and Image Processing